一、前言
MysqlDump常用于实现轻量级的快速迁移或数据库全量备份。
MysqlDump属于逻辑备份,原理是将数据表导成 SQL 脚本文件。兼容性好,支持不同版本数据库之间的迁移。但因其效率问题,仅适用于数据量小的场景使用(比如只有几个G)
当数据量较大的时候,比如大于 50G,建议使用物理备份,比如Xtrabackup、MEB;如果可以停机冷备的话,可以考虑用kettle同步数据。Xtrabackup 备份可看本站另一篇文章。
MEB(MySQL Enterprise Backup),又称 MySQLBackup,Oracle 官方推出的企业版物理备份工具,由于需要收费,这里不考虑。
二、评估
1、数据量评估
选择何种迁移方式很大程度取决于数据库的数据量,所以要知道现有数据库的大小。优先迁移小库,其次是大库中的小表,最后迁移大库中的大表。我个人常用的评估有两种方式:
1、通过 SQL 查询
# 汇总所有库的总大小
SELECT SUM(data_length + index_length) / 1024 / 1024 AS total_mb FROM information_schema.TABLES;
# 分别列出各个库的大小
SELECT table_schema AS db_name, SUM(data_length + index_length) / 1024 / 1024 AS total_mb
FROM information_schema.TABLES
GROUP BY table_schema;
# 大库一般是某几张表比较大,列出各个表的大小 (推荐使用!!!)
select table_name, SUM(data_length + index_length) / 1024 / 1024 AS total_mb,
SUM(data_length) / 1024 / 1024 AS data_mb,
SUM(index_length) / 1024 / 1024 AS index_mb
from information_schema.TABLES
where table_schema = 'big_database_name'
group by table_name
order by SUM(data_length + index_length) desc2、数据库 data 目录大小
比如公司使用的宝塔,找到 Mysql 数据的目录,比如 /www/server/data,点击计算,可以大概知道数据量有多大。
2、带宽评估
为了灾备,一般服务器迁移都是不同地域迁移,可使用 ② 方案。云存储,例如 OSS,一般每月都有免费额度。
① 同云服务商同地域迁移,组内网,服务器内网一般是千兆带宽,完全满足传输的需求。
② 不同地域迁移、源地域有 OSS 之类服务,使用 OSS 作为中间媒介,源服务器通过内网上传数据到 OSS,目标服务器通过公网下载 OSS 文件。也就是源服务器和源 OSS 组内网,这样做不用走服务器的带宽(上行)。
③ 不同地域迁移、无类 OSS 服务,可考虑云服务商(如阿里云)的临时带宽升级。3M 带宽临时升级 3个小时(阿里云最低 3个小时),100M 约花费 40元,200M 约 80元。
个人迁移经验:
公司服务器从沃云迁移到阿里云,无OSS,因各种原因也升级不了带宽,整个传输过程极其漫长,迁移的瓶颈就是带宽。总体数据有 43G,4Mbps带宽,跑满带宽理论要传 24个小时。
最终传了 3天,原因有三:
有网站应用运行,会占用一部分带宽
服务器磁盘不足,一个大数据表导出可能就要占满了。只能传完一批数据后,删除导出数据和压缩包,之后再导出。
因为工作繁忙或者凌晨休息,传输完的一批文件后不能接着传输下一批。
三、MySQLDump
1、基本参数
灰色高亮表示无须特别关注。不关注原因有二:默认配置已经满足我们的需求,比如字段备注导出,我们只需要知道 MySQLDump 默认会导出备注即可;还有就是日常用不上功能的配置,比如触发器、函数这种一般 DBA 都不允许使用的东西。
(1)--master-data(可选、主从可考虑)
该参数会使用 change master 语句把 bin-log 的 filename 和 position 写入到 dumpfile 里面。默认为 0、off,不输出 change master 语句。启用该选项将会同时启用 --lock-all-tables,除非指定 --single-transaction。change master 请看本站 mysql 主从搭建的文章,了解它的作用,简单说就是同步主从两边 bin-log 的位置。
master-data=1
设置为 1 会将 change master 语句写进 dump 文件中。从库导入 dump.sql 后无需再指定文件名和位置了。
mster-data=2
同样会写入到 dump 文件中,但是会注释掉。从库同步设置要手动指定文件名和位置。建议使用该值。
使用该参数 mysqldump 可能遇到的问题:
# Q1: mysqldump: Couldn't execute 'FLUSH /*!40101 LOCAL */ TABLES': Access denied; you need (at least one of) the RELOAD privilege(s) for this operation (1227)
# A1: 解决办法-赋予用户RELOAD权限:
GRANT reload ON *.* TO 'backup'@'localhost'; flush privileges;(2)--events,-E:定时任务(可选,不推荐使用定时任务)
使用该参数 mysqldump 可能遇到的问题:
# Q1: mysqldump: Couldn't execute 'show events': Access denied for user 'root'@'localhost' to database 'xxx' (1044)
# A1: 解决办法
赋予用户RELOAD权限:GRANT event ON *.* TO 'backup'@'localhost'; flush privileges;(3)--routines, -R:所有的存储过程和函数(可选,不推荐使用存储过程和函数)
(4)--comments,-i:表字段备注,默认。
(5)--triggers:触发器。默认启用,可使用 --skip-triggers 关闭。
(6)--ignore-table=database.table:忽略某张表,须指定 database。忽略多张表可多次使用此指令。
(7)--no-data,-d:No row information
(8)--no-create-info,-t:Don't write table creation info
(9)--all-databases,-A:备份所有数据库。生成 create database if no exists 和 use database 语句。5.7.44 默认不会导出 performance_schema、sys、information_schema。
(10)--databases,-B:备份多个数据库。生成 create database if no exists 和 use database 语句。
(11)--flush-logs,-F:日志滚动。完整恢复=全量备份(dumpfile)+ 增量(滚动 bin_log)
(12)--quick,-q:直接导出不写入内存,默认,使用 --skip-quick 关闭。节省内存,但因为是边查询边输出,而不是查询完再输出,输出效率可能会变慢。
(13)--single-transaction:备份期间不锁表,使用 innodb引擎 保证数据一致性。该选项会 disable:--lock-all-tables、--lock-tables(用于快照备份、热备份)
(14)--lock-all-tables,-x:锁定所有库的所有表,该选项会 disable:--single-transaction,--lock-tables
(15)--lock-tables,-l:锁定所有表,默认,可使用 --skip-lock-tables 关闭
# 问题:Access denied for user 'root'@'localhost' to database 'test_backup' when doing LOCK TABLES
# 解决方法
GRANT lock tables ON *.* TO 'backup'@'localhost'; flush privileges;(16)--add-locks:给 intert 语块加上 Write Lock,导入时锁表。默认,可使用 --skip-add-locks 关闭
(17)-T,--tab=path:生成表结构 SQL 和 数据 TXT 文件,path 为生成的目录地址(必须存在)。大表建议使用,后续配合 load data infile 导入,效果显著。
测试例子:100W数据,使用 insert 每分钟插入约 4000条,预计要花费 4 个多小时完成;使用load data infine 仅花费 8s。
# 问题一: mysqldump: Got error: 1045: Access denied for user 'root'@'localhost' (using password: NO) when executing 'SELECT INTO OUTFILE'
# 解决方法
GRANT FILE ON *.* TO 'root'@'localhost';flush privileges;
# 问题二: mysqldump: Got error: 1290: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement when executing 'SELECT INTO OUTFILE'
# 解决方法:请看后续的【扩展设置】secure-file-priv(18)--compact:紧凑模式。减少注释、不加锁等,用于测试表快速导出,没有锁和事务可能存在不一致的问题(这个命令几乎不用)。启用:--skip-add-drop-table、--skip-add-locks、--skip-comments、--skip-disable-keys、--skip-set-charset
(19)--set-gtid-purged:用于 GTID 复制,未仔细研究。值为 ON 时会加上语句 SET @@SESSION.SQL_LOG_BIN= 0,导入 dumpfile 将不会记录到 bin-log
(20)--add-drop-database:生成 drop database if exist,需要配合 -A 或 -B 使用,否则无效。几乎没有使用场景,可设想的场景就是复制生产 dump 库到测试环境测试,不过这种场景下也不会选择用它,一般是通过 Navicat 删除库然后重新创建。(不推荐使用,删错很严重)
(21) --skip-add-drop-table:避免生成 drop table if exists 语句。在主库导出、备库导入的场景,避免操作人员选错环境在主库执行了导入,实测 15G 的表使用 load data infine 导入数据 + 创建索引花了 1h20min,涉及该表的查询、操作需要等 1h20min 才能正常响应,想想就知道有多恐怖 😱 😱😱。15G 是指在 mysql 中的占用,数据占 5G,10G 索引。
2、执行用户权限
GRANT select, reload, lock tables, replication client, show view, event, trigger, file ON *.* TO 'root'@'localhost';flush privileges;3、扩展设置
(1)secure-file-priv
secure-file-priv 决定了能否有权限使用 LOAD DATA, SELECT ... OUTFILE 以及使用的安全目录。
当 secure_file_priv 的值为 null ,
secure_file_priv=表示示不允许导入、导出。当 secure_file_priv 的值为 /tmp/ ,
secure_file_priv=/tmp,表示导入、导出只能在 /tmp/ 目录下。当 secure_file_priv 的值没有具体值时,
secure_file_priv='',表示不做任何限制。
如何设置?
step1:my.cnf 文件 [mysqld] 后加上 secure_file_priv=/tmp 或 secure_file_priv=''。实测 secure_file_priv=/root/xxx 不生效,建议不要设置 /root/xxx;secure_file_priv=''对 /root 下文件夹也不生效,文件不要放到 /root 文件下。
step2:赋予权限(文件创建):chmod -R 777 /tmp
step3:重启 mysql,systemctl restart mysqld
step4:查看:SHOW VARIABLES LIKE '%secure%';
(2)master-data 和 single-transaction 使用注意事项
master-data和single-transaction同时使用一般是用来搭建主从。日常备份建议使用 single-transaction,不建议使用 master-data。
原因是 master-data 会执行 flush tables,需要获取库级别的全局读锁,在业务高峰期(大量 DML 执行)获取全局锁很困难,最终导致大量连接出现 waiting for table flush(可通过 show processlist 查看到)。master-data 相比 --lock-tables 获得的锁时间非常短,但一旦出现 waiting ... flush 的情况, select 语句也会被阻塞,这对业务系统来说是灾难性的。如果不幸出现这种灾难状况,你需要快速定位 lock 住的线程,kill 掉它。
4、导出
(0)导出必知
配合 --single-transaction 使用避免长时间锁表导致的一系列问题。
-B、-A 会在 dumpfile 会增加 create database if not exists 语句。
优点:免去 create database 的工作
缺点:如果有同名数据库,数据会覆盖。create database 可以增加一步确认的保障。PS:在之前的迁移演练中,曾出现因操作环境确认不到位,险些在错误的数据库实例上执行变更脚本的风险事件。
建议:不要用 -A、-B,手动创建、手动指定
(1)单个库导出
mysqldump -u root -p -B mydatabase > backup.sql
# 库数据较大, 导出时长较长, 使用事务避免长时间锁表影响业务
mysqldump -u root -p --single-transaction -B mydatabase > backup.sql(2)单个库导出 + 忽略部分表
mysqldump -u root -p --ignore-table=mydatabase.table1 --ignore-table=mydatabase.table2 -B mydatabase > backup.sql(3)单个库导出 + 指定部分表
mysqldump -u root -p mydatabase table1 table2 > backup.sql(4)导出部分库
mysqldump -u root -p -B db1 db2 > backup.sql(5)所有库导出
会导出 Mysql 的自带的库 mysql,不建议使用所有库导出。不存在 --ignore-database 选项。
mysqldump -u root -p --all-databases > all_databases_backup.sql(6)只导出表结构
一般用于分批迁移,先创建好所有表结构,提前迁移历史明细表、日志表等大表。正式迁移那一晚,Mysql 停机,迁移剩下的(小表)动态数据。
后续可能还会通过 sql、程序补偿大表的增量数据。
# 所有表结构
mysqldump -u root -p -d -B mydatabase > backup.sql
# 部分表结构
# 不能用 -B, 不需要 db.table1
mysqldump -u root -p -d mydatabase table1 table2 > backup.sql(7)导出部分数据
# -t: --no-create-info
mysqldump -uroot -p --single-transaction -t my_database my_table --where="created_at > '2023-01-01'" > recent_data.sql
(8)大表导出(后续配合 load data infile)
# 1.1 单表导出, tmp 目录下会生成 tableName.txt 和 table.sql 两个文件
# 重复执行, 会覆盖之前的文件。
mysqldump -uroot -p --single-transaction -T /tmp databaseName tableName
mysqldump -uroot -p --single-transaction --tab=/tmp databaseName
# 1.2 多表导出, 表名空格隔开
mysqldump -uroot -p --single-transaction -T /tmp databaseName table1 table2 ..
# 2. 或者登录 mysql 执行 sql
select * from tableName into outfile '/tmp/xx.csv'PS:多表导出会有多个文件,怎么压缩成一个文件?答:zip archive.zip *.txt *.sql
5、导入
(1)导入优化
# load data infile 测试:
# test1 导入 1G 数据 (800M data + 200M index)
# test2 导入 8G 数据 (6G data + 17G index)
# 1、关闭 binlog (2min16s、88m24s, 推荐)
/etc/my.cnf 注释 log-bin, 重启 mysqld, 执行命令验证: show variables like 'log_bin%'
# 2、关闭唯一校验、自动提交 (2min12s、88m22s, 效果不明显, 不推荐)
mysql -u root -p -e "set unique_checks=0;set autocommit=0;load data infile '/tmp/employee.txt' INTO TABLE employee;set autocommit=1;" database_name
# 3、事务日志落盘改为每秒一次 (39s、79min6s, 推荐)
修改 /etc/my.cnf, innodb_flush_log_at_trx_commit 改为 0, 重启, 验证: show variables like 'innodb_flush_log_at_trx_commit'
# 3.1 导入完记得改回 1(2)sql 导入
创建 database:
如果 sql 文件中没有 create database if not exists 则需要先创建:
# -e 表示 execute, 执行指定的 sql
mysql -u root -p -e "CREATE DATABASE database_name"# 1、dumpsqlfile 文件有 use database 语句
mysql -u root -p < backup.sql
# 2、sql 文件没有 use database (通用, 推荐)
mysql -u root -p database_name < backup.sql
# 3、登录 mysql 客户端, 执行 sql
use database_name; source /tmp/backup.sql;
# 4、另一种写法
mysql -u root -p -e "source /tmp/backup.sql" database_name(3)load data infile 导入
针对数据量大的、10G以下的单表,10G以上请使用 mysqldumper 或 mysqlpump。
准备工作:创建好数据表且表数据为空
# 1、导出 txt 文件里面, NULL 字段对应是 \N, 测试过导入正常。
LOAD DATA infile '/tmp/employee.txt' INTO TABLE employee
# 2、不用登录进 mysql 客户端执行
mysql -u root -p -e "load data infile '/tmp/employee.txt' INTO TABLE employee" your_database
# 3、后台执行。超大数据量要执行数个小时,直接执行关闭SSH终端会中断
nohup mysql -u root -p your_database -e "LOAD DATA INFILE '/path/to/your/file.csv' INTO TABLE your_table;" &网上看到的问题(可能是低版本的问题),NULL字段导出导入后据说会自动赋值为空串、日期类型0点、数字类型0等,我这边没有遇到。贴上解决办法:
# 将 title、join_date、gender 读到变量中,后续重新赋值。
LOAD DATA infile '/tmp/test_table.txt'
INTO TABLE test_table
fields
terminated BY ","
lines terminated BY "\n"
(id, name, @title, @join_date, @gender)
SET
title= nullif(@title, ''),
join_date= nullif(@join_date, ''),
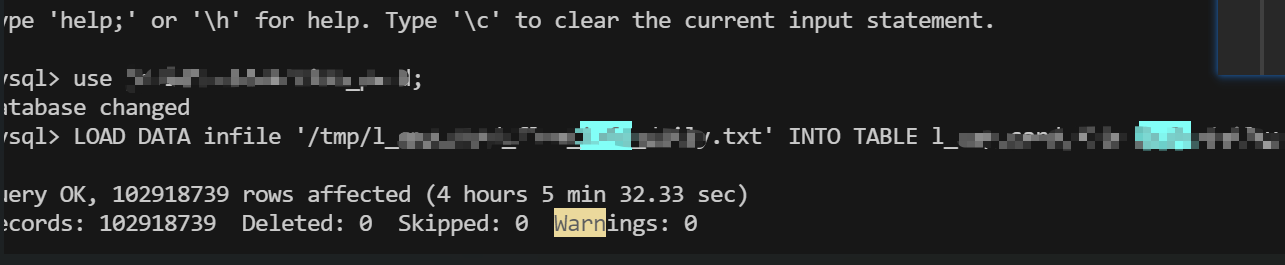
gender= nullif(@gender, '')为何数量大的导入不建议用 load data infile?
参考下图,1亿行(10G Data、32.9G Index),导入花费 4h5min32s,极其耗时。
6、终止 Dump
MySQLDump 导出的时候,如果我们既没有用事务(single-transaction)也没有过滤掉一些不用的大表,可能会因为锁表导致应用大面积的请求暂停、页面白屏。此时,我们需要 kill 掉不合理的 MySQLDump 进程,恢复应用。